0. 들어가며
데이터 분석가가 분석 프로젝트를 진행할 때 80%의 시간을 전처리에 사용한다고 합니다.
데이터 사이언티스트도 마찬가지, 모델링을 하기 위해서는 내가 원하는 형식의 데이터 셋 구축이 필수적입니다.

제조 데이터를 활용한 예측 모델링 업무를 수행하며 대부분의 전처리 방식은 동일하나, 일부는 제조 도메인에서 자주 사용된다는 것을 알게 되었습니다.
이 글은 데이터 전처리에 대한 기본적인 지식을 가지고 있으며, 제조 도메인이 궁금한 분들에게 추천드립니다.
1. 데이터 전처리 (Data Preprocessing) 이란?
데이터 분석을 흔히 요리로 비유하는데요, 전처리는 요리의 재료를 손질하는 부분이라고 말합니다.채소를 씻고, 적당한 크기로 자르고, 필요없는 부분은 버리기도 하죠. 그래야 재료 준비가 완성됩니다.
마찬가지로 데이터 전처리를 하는 목적도 분석 목표에 맞게 필요한 데이터만 추출하기 위함입니다.
[ 제조 분야의 데이터 예시 ]
- 태그 데이터 : 설비에 오류가 발생하거나 공장 TA(=정기보수) 기간에는 데이터가 수집이 되지 않거나, 이상한 데이터가 저장되기도 합니다.
- 품질 데이터 : 수기로 작성되는 경우도 있고, 실험 후 사람이 엑셀에 직접 데이터를 입력하는 경우도 있습니다. 이 과정에서 human error가 발생하기도 합니다.
신뢰할만한 분석은 Clean data에 달려 있습니다. Clean data만이 Clean한 결과를 도출해낼 가능성이 높아지죠.
그럼 이제부터 그 방법을 알아봅시다 !
2. 데이터 전처리의 종류
▣ 이상치 (Outlier) 처리
- 이상치 제거
- 평균/중앙값 대체
- 최솟값/최댓값 대체
- 데이터 재수집
이상치를 처리하는 방법은 위와 같이 주로 4가지 방법론을 주로 이용합니다.
처리 방법은 간단하나 "그래서 어디부터 어디까지가 이상치야?"를 정하는 것이 어려운데요, 가장 대표적인 방법 2가지를 소개합니다.
(1) IQR ; Inter Quantile Range
IQR을 이해하려면 아래 그림으로 설명하는 것이 가장 쉬운데요,데이터를 오름차순 정렬 후 4등분하여, 순차적으로 Q1, Q2, Q3라 칭합니다.
MIN (0%) - Q1 (25%) - Q2 (50%, 중앙값) - Q3 (75%) - MAX (100%)

여기서 IQR은 Q3-Q1, 즉 중앙의 50%에 해당하는 데이터의 최대와 최소의 차이를 뜻합니다.
Q1 - 1.5 * IQR을 최댓값으로, Q3 + 1.5 * IQR을 최댓값을 Clean 데이터로 취급하고, 그 외의 값들을 이상치로 보는 방식입니다.
(2) 6 시그마 (6-sigma)
제조 분야에서 가장 자주 사용되는 방법으로, 평균으로 부터 ±표준편차 * 시그마계수에 해당하는 데이터만 Clean data로 취급합니다. (표준편차 == 시그마)

위 그림을 확인해보면, 6시그마가 IQR 방식보다 조금 더 보수적인 방식임을 확인할 수 있습니다.
▣ 결측값 처리
- 단순 제거
- 평균/중앙값 대체
- 데이터 재수집
결측값 처리의 방법은 더욱 간단합니다. 이번에도 역시 결측값 판단 기준에 대해 예시로 알아보겠습니다.
[ 제조 분야의 데이터 예시 ]
- 열 (column) 기준 처리가 필요한 경우
: 특정 X인자의 값이 특정 임계값(ex.60%) 이상의 결측이 있으면, 해당 X인자는 유의미한 인자로 도출될 수 없습니다. 불량 인자 도출, 예측 모델링 등의 제조 분석에서 모수가 부족하여 Y와의 관계 파악 자체가 불가능합니다.
- 행 (row) 기준 처리가 필요한 경우
: 하나의 행이 제품 하나의 데이터인 경우, 행에서 특정 임계값 이상의 결측이 있으면 행 자체를 제거합니다. 예를 들어, 특정 batch의 센서값이 측정 되지 않거나 수기데이터가 누락되었을 경우에는 이상 batch라고 판단하여 제거합니다.
▣ 데이터 통합
- JOIN
여러개의 데이터 셋을 하나의 데이터 셋으로 합치는 과정입니다.
[ 제조 분야의 데이터 예시 ]
주로 제품 단위 (ex.BATCH명, LOT명) 혹은 시간 등의 변수를 JOIN KEY로 JOIN을 합니다.
- 체류시간을 고려한 전처리
[ 제조 분야의 데이터 예시 ]
체류시간이란 어떤 공정에서 원료가 설비 안에 머무르는 시간입니다. 화학 공정은 배치(batch) 공정이 아닌 연속 공정으로 대부분의 공정이 연속적으로 진행됩니다. 따라서, 원료의 양이나 흐르는 속도에 따라 공정 시간이 달라지게 됩니다.
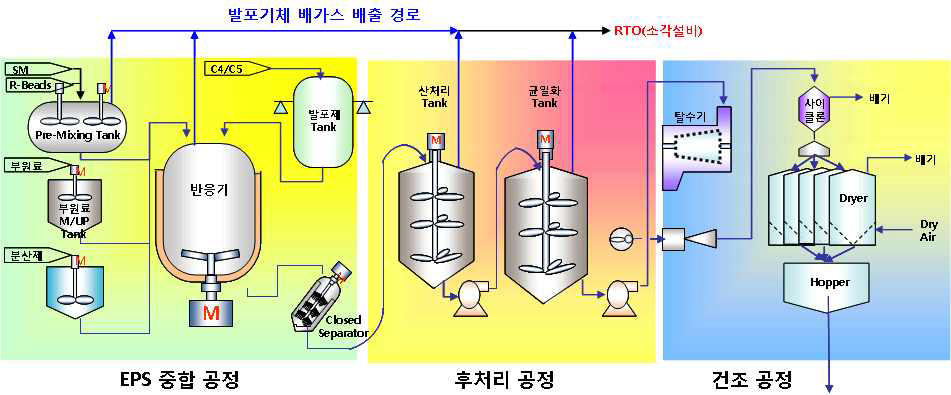
석유화학 공정을 예를 들어 봅시다.
본 공정은 중합 - 후처리 - 건조 공정 순으로 진행됩니다.
중합 공정이 3시간, 후처리 공정이 2시간, 건조 공정이 1시간이라 가정하면 본 공정은 총 6시간이 걸립니다.
물성 검사는 공정의 마지막에 진행한다고 합시다.
그렇다면 중합 공정이 1시에 시작이 되었으면, 해당 품종의 물성 값(Y)은 7시에 수집되게 됩니다.
"중합 공정의 센서 데이터(X) 와 품질(Y) 과의 상관성을 알아보자"를 주제로 분석을 하고 싶은 경우에, 센서 데이터(X)와 물성 데이터(Y)를 결합해야 합니다.
X+Y를 할 때, 데이터 수집 시간을 기준으로 결합을 합니다. 따라서 본 예시에서 단순히 물성 값(Y) 을 기준으로 센서 데이터(X) 를 붙이면(LEFT or RIGHT JOIN) 센서 데이터(X)는 7시에 수집된 이상한 데이터로 붙게 되겠죠?
따라서 체류시간을 고려하여, 조인키(JOIN KEY)인 시간을 조절해주어야 합니다.
체류시간은 주로 현장에서 관리하고 있어, 현업과 소통하며 데이터를 결합하는 과정이 필수적입니다.
여기까지만 데이터 셋을 만들어도 모델링이 가능하지만 데싸에게 중요한 건 "결과", 즉 "모델의 성능"이겠죠
다음 글에서는 모델의 성능을 높이기 위해, 제가 자주 사용하는 전처리 방법에 대해 소개하겠습니다 :)
'DATA ANALYSIS > in 제조 분야' 카테고리의 다른 글
| 쉽게 정리하는 이상 탐지(Anomaly Detection) - 정의, 종류, 제조 분야에서의 활용 (0) | 2024.07.30 |
|---|---|
| 제조 데이터에서의 전처리란? (2) (for 모델링) (0) | 2024.05.11 |
| 제조 도메인에서의 데이터 분석과 AI 활용 (2) | 2024.01.21 |


