1. Data-based Melt Index Prediction in Styrene-Acrylonitrile Polymerization Process (2021.06)
- 실제 공정 데이터를 사용해 6가지 모델의 예측 성능 테스트 실시
- 학습 데이터 : 1,029개 / 테스트 데이터 : 115개
Y : MI 값
- 4시간마다 실험을 통해 얻어지며, 두 등급의 고분자에서 서로 다른 범위를 가짐)
X : 9개 측정 변수
- 각 단량체의 유량 및 재사용 단량체의 총 유량과 개시제 유량, 각 반응기의 온도 및 압력 등을 센서를 통하여 1시간마다 측정
- MI가 측정된 시간부터 이전 4시간 동안 입력 변수들의 평균값을 계산하여 모델의 입력으로 사용
- 두 가지 등급의 고분자 생산 데이터가 혼재되어 있으며 공정의 일시 중단 등 비정상 상태의 데이터 또한 포함

- 여기서 ANN이란 사실 상 DNN이다.
2. Hybrid modeling approach for polymer melt index prediction (2022.07)
- White-box 서브모델 적용 후 Black-box 서브모델로 이어지는 연속적 구조인 hybrid model을 제안
→ 예측 및 일반화 성능을 향상
1. White-box : 공정과 polymer 제품의 현재 상태에 대한 정보를 계산함 (ex. weight-average and number-average molecular weights 등)
- Mechanic modeling을 통한 White-box의 output은 MI의 더 정확한 예측을 하게함
→ 이 변수와 특정된 데이터가 함께 Black-box의 입력값으로 사용
2. Black-box : MI를 추정하기 위한 머신러닝 모델 하이브리드 모델링

[ 데이터 설명 ]
–약 17개월간 공정 및 품질 측정 자료 (2020년 1월 2일부터 2021년 5월 23일)
Y : MI 값 (펠레타이저에서 채취한 고분자 시료의 MI 및 색상)
- 4시간마다 측정
X : 27개 공정 변수
- 측정 오류 및 종료 데이터를 제거한 후 모델링에 사용할 수 있는 MI 측정 데이터 2285개
- reactor와 탱크의 온도, 압력 및 레벨, 단량체/개시제/재활용 스트림의 유량 측정, 프로세스에서 펌프 작동에 필요한 전류
- 센서를 통하여 1시간마다 측정
- MI가 측정된 시간부터 이전 4시간 동안 입력 변수들의 평균값을 계산하여 모델의 입력으로 사용
[ 전처리 ]
- 표준화
- 다중공선성 제거를 위한 PCA 적용
: 44 PCs → 10 PCs(93.1%의 설명력)로 모델 계산 비용 절감

[ 모델링 ]
–데이터 분리 비율 : Train : 80% / Test : 20%
–GPR 모델은 quasi-Newton optimization로 학습
–ANN 모델의 활성화 함수는 hyperbolic tangent
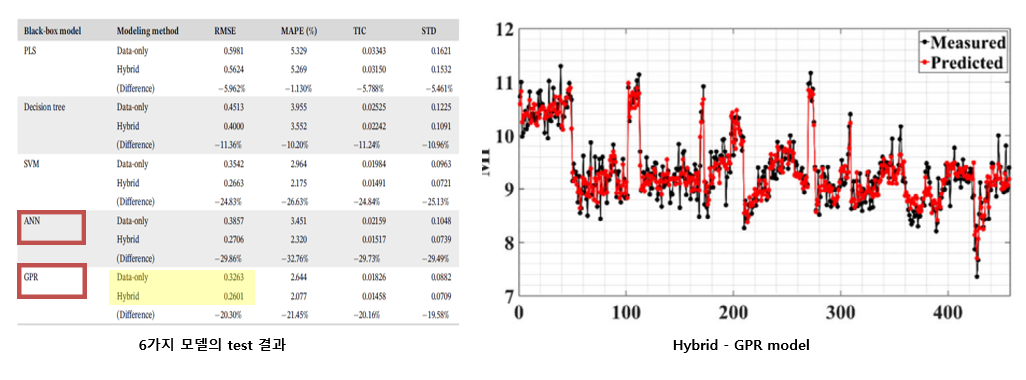
–Hybrid modeling과 data-only modeling 2가지 방식 모두 GPR 모델의 예측 성능이 가장 높았음
- 평가지표 : RMSE, MAPE, TIC, STD
'AI > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] EfficientNet : Rethinking Model Scaling for Convolutional Neural Network (0) | 2023.12.10 |
|---|
